集合框架
Collection 类关系图
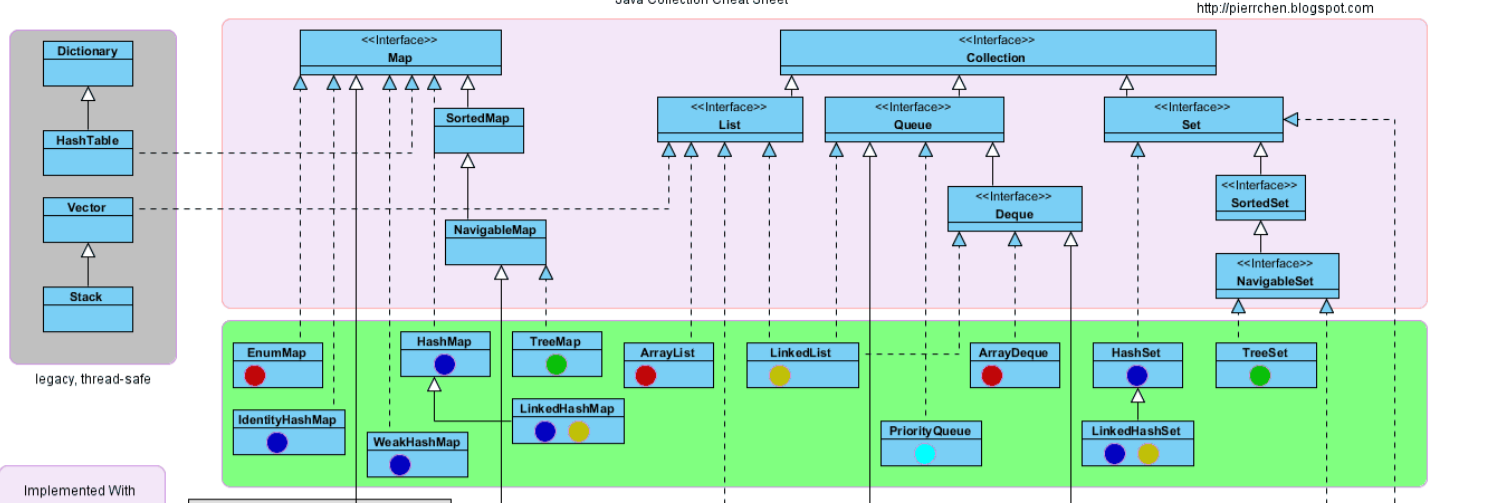
有两个顶层接口:Collection 和 Map
Map 接口下的常用实现类:TreeMap、HashMap、HashTable、LinkedHashMap
Collection接口下又衍生出了三个接口:List、Queue、Set
List 接口下的常用实现类:ArrayList、Vector、LinkedList
Set 接口下的常用实现了类:TreeSet、HashSet、LinkedHashSet
Queue 接口下的常用实现类:LinkedList、ArrayDeque、PriorityQueue
ArrayList 详解
特点
- 底层基于数组实现,数组空间不够时,可自动扩容
- 允许放入
null值 - 非线程安全
底层数据结构
private static final int DEFAULT_CAPACITY = 10; // 默认初始化容量
private static final Object[] EMPTY_ELEMENTDATA = {}; // 空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // 默认空数组
transient Object[] elementData; // 对象数组,底层的存储容器
private int size; // 数组中元素数量,即列表大小
构造函数
// 指定底层数组的初始化长度
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
// 默认是空数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 也可以放入一个协变类型的集合
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
自动扩容机制
// 我们一般会调用的函数
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
// 实际上会调用的函数(方法的重载)
private void add(E e, Object[] elementData, int s) {
// 如果当前元素的数量等于底层数组打的长度,那么执行扩容操作
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
// 我们还可以一次性添加很多
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
// 被添加元素集合中的元素数量大于了剩余空间长度,会执行扩容
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
System.arraycopy(a, 0, elementData, s, numNew);
size = s + numNew;
return true;
}
// 扩容函数的实现
private Object[] grow() {
return grow(size + 1);
}
// 实际上调用的扩容函数
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
总结下来:
- 每次列表中添加元素时,都会先检查底层数组的剩余长度是否可以容纳所添加元素的数量,如果装不下,则会调用对应的扩容函数,执行扩容操作
- 数组进行扩容时,首先创建一份比自己大
1.5倍长度的数组,然后将原有数组中的所有元素全部拷贝到新的数组,在新的数组中添加元素,最后指向新数组。
如果添加数量可预知的话,可以调用ensureCapacity()方法,传入一个最小数组容量,避免这种递增式的容量扩张。
时间复杂度相关
对列表的增删改查,就是对数组的增删该查,相信学过数据结构与算法的你,肯定知道的。
Fail-Fast机制
基本上能够被迭代的数据结构都实现了这个机制,原理就是在集合内部维护着一个modCount(修改计数器),迭代器创建之前会将当前的modCount保存一个局部变量副本,迭代过程中,不断检测modCount是否与副本的值相等,如果不相等,就会抛出异常,表示在迭代的过程中,集合的数据结构被修改了。
LinkedList 详解
特点
- 底层基于链表实现的,是一个双向链表
- 允许放入
null - 非线程安全
底层数据结构
transient int size = 0; // 元素数量,即链表大小
transient Node<E> first; // 链表头部节点
transient Node<E> last; // 链表尾部节点
构造函数
// 啥也没有
public LinkedList() {
}
// 调用无参构造器,添加协变类型的元素
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
最后
这玩意儿没有什么好说的,就这样吧。
Vector 详解
特点
- 它就是一个“上了锁”的
ArrayList,对底层数组进行操作的方法都加上了syncornized关键字 - 线程安全
ArrayDeque 详解
特点
- 底层通过数组实现,是一个循环数组
- 不允许放入
null元素 - 非线程安全
底层数据结构
transient Object[] elements; // 对象数组
transient int head; // 头部插入索引
transient int tail; // 尾部插入索引
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 数组最大长度
扩容机制
和ArrayList的差不多,只不过是申请的新数组的大小是原数组的两倍。
PriorityQueue 详解
特点
- 逻辑上基于完全二叉树实现的小顶堆,堆顶每次取出的元素都是整个队列中权重值最小的,实际上底层数据结构是数组。
- 不允许放入
null元素 - 非线程安全
底层数据结构
private static final int DEFAULT_INITIAL_CAPACITY = 11; // 默认数组长度,即队列大小
transient Object[] queue; // 底层数组
int size; // 数组中元素的数量,即队列的大小
@SuppressWarnings("serial")
private final Comparator<? super E> comparator; // 默认构造器
transient int modCount; // 修改计数器
时间复杂度
- 插入和删除操作的时间复杂度都是 O(logn)
- 队列的清空操作是是O(n)的
HashMap 详解
特点
- 底层基于数组 + 链表,JDK 8 及之后的版本又引入了红黑树。
- 类似于字典一样的操作,通过指定的
key经过哈希计算拿到对应的value时间复杂度近似O(1) key和value允许放入null值- 非线程安全
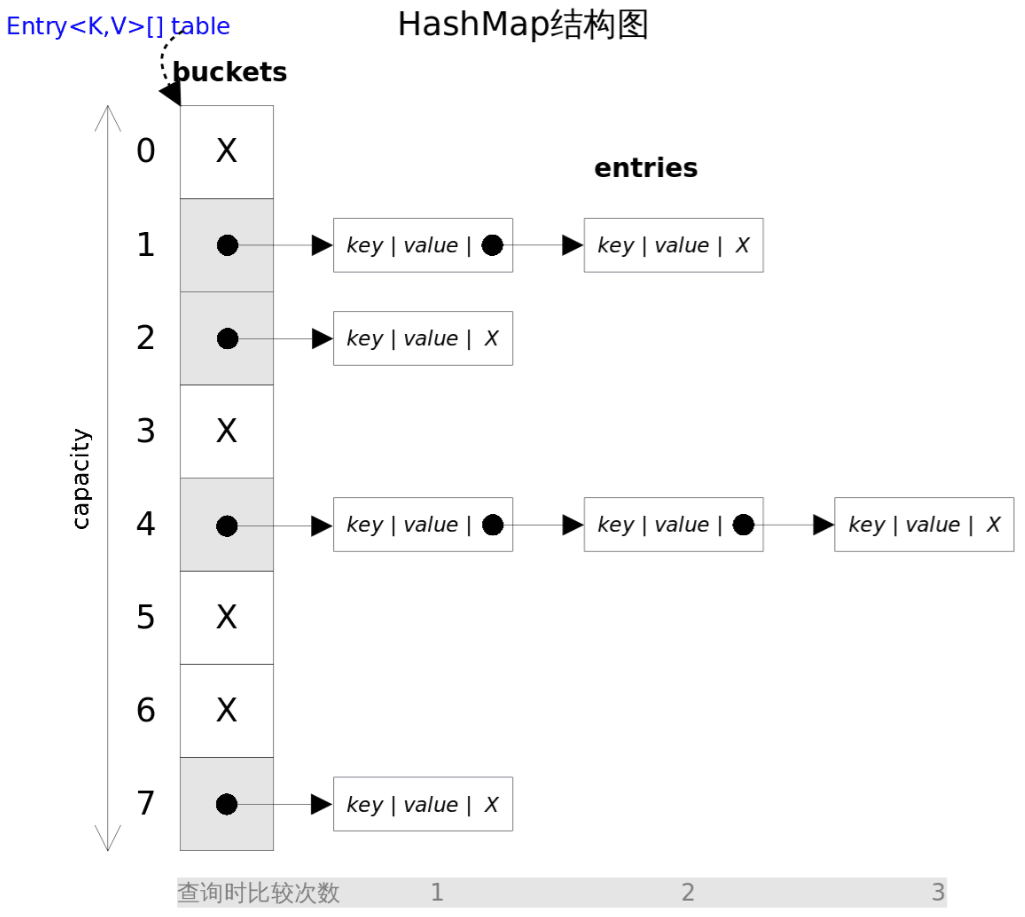
底层数据结构
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认初始化大小,结果是16
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大的容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认负载因子
static final int TREEIFY_THRESHOLD = 8; // Bucket中链表转红黑树的阈值
static final int UNTREEIFY_THRESHOLD = 6; // Bucket中黑红树转链表的阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 哈希表的最小容量,控制链表与红黑树的转化
transient Node<K,V>[] table; // 底层数组
transient Set<Map.Entry<K,V>> entrySet; // 所有键值对的集合
transient int size; // Entry<K,V>的个数,即哈希表的大小
// 放入桶中的节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; // 链表
// ... 其余代码
}
所谓的Bucket其实就对应着底层数组的“槽位”,即每一个索引位。
哈希冲突
不同的对象的hash值可能会相同,也就是说会命中同一个Bucket,和原来桶中的对象发生了冲突。解决哈希冲突的方案也有很多,HashMap采用了链地址法,即将hash值相同的元素以链表的形式进行存储,冲突的元素加入到链表尾部。
扩容机制
触发条件
哈希表中
Entry<K,V>的数量达到负载因子 * 底层数组长度时,就会触发扩容扩容的过程
- 申请一个新的数组,新数组的大小是原数组的两倍
- 将原有桶中的
Entry<K,V>全部重新hash(rehash)到新的桶上
扩容的时间复杂度是O(n),因为要遍历整个
HashMap中的元素,而且还要重新进行hash计算,分配到新的桶中,是一个比较耗时的操作。
链表与红黑树的转换
这里需要三个条件配合:
TREEIFY_THRESHOLD:单个桶中链表转红黑树的阈值,默认为8
UNTREEIFY_THRESHOLD:单个桶中红黑树转链表的阈值,默认为6
MIN_TREEIFY_CAPACITY:控制链表树化的阈值,默认为64
- 哈希表的容量小于64时,优先进行扩容,而不是链表的树化
- 哈希表的容量超过或者等于64时,并且链表的长度超过8时,会进行树化操作
- 当红黑树的节点数量小于或等于6时,红黑树会退化成链表
为什么转换的阈值不一样?
避免在两者之前反复横跳,增加不必要的转化开销。
HashSet 详解
直接看构造函数吧:
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
很清晰的了,本质上就是HashMap了嘛。只不过Value是一个固定的对象,每一个Entry<K,V>中的Value都指向这个对象。
LinkedHashMap 详解
看名字都知道肯定与HashMap有关系:
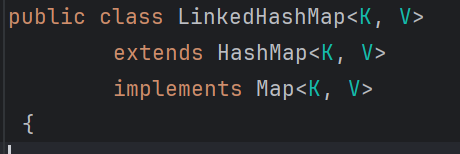
没错,它就是HashMap的直接子类,主体上和HashMap差不多,只不过内部将所有的Entry<K,V>串了起来,形成了一个双向链表:
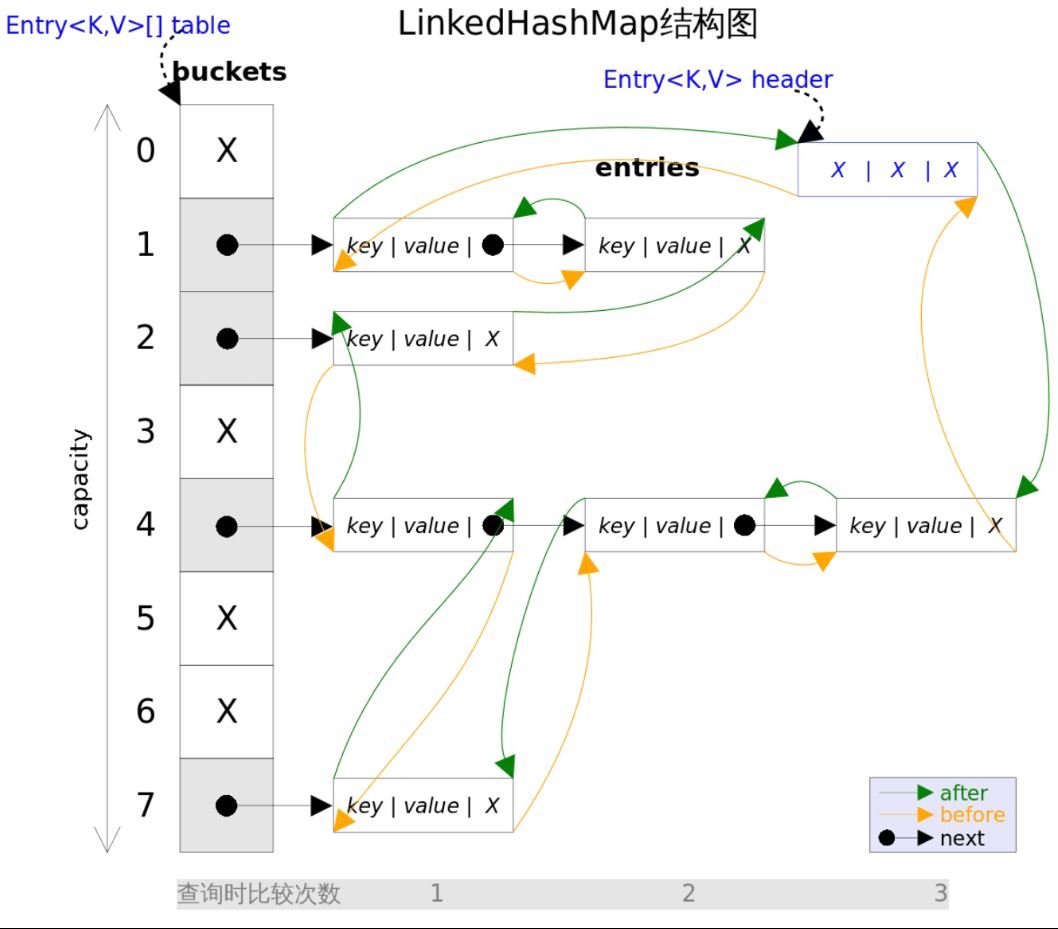
这样做就保证了迭代顺序和插入顺序相同。另一个优势就是不用遍历所有的桶就可以找出所有的节点。
transient LinkedHashMap.Entry<K,V> head; // 头节点的哨兵节点
transient LinkedHashMap.Entry<K,V> tail; // 尾节点的哨兵节点
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 前一个节点引用和后一个节点引用
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
双向链表示意图:
head <-> Entry1 <-> Entry2 <-> ... <-> EntryN <-> tail
哨兵节点的作用就是找到它的前一个或者下一个节点。
LinkedHashSet 详解
“披着羊皮的狼”,本质上还是LinkedHashMap:

这不能说明什么,虽然我们知道HashSet基于HashMap的,但是没有体现出Linked。让我们看看HashSet中的具体实现吧:

看见没,如果你去追查了LinkedHashSet的源码,你就会发现它的所有构造器都在调用父类HashSet的这个构造器,真相大白。
TreeMap 详解
特点
- 底层基于红黑树实现,也是存储
Entry<K,V>的,只不过会按照Key的自然顺序或者自定义构造器对Entry<K,V>进行排序存储 Key不能为null- 非线程安全
其他
难道你指望我给你讲明白红黑树???(我菜,手撕不出来)
我只能给你说点注意事项,TreeMap中每一个键值对的Key是唯一的,如果出现重复的,后来者居上,也就是会覆盖掉原来key的value。(红黑树是一种近似平衡的二叉查找树,而二叉搜索树的一般定义中也是不存在重复元素的)
当然,红黑树的增删改查的平均时间复杂度都是O(log n),非常的高效。(实现起来也复杂)
TreeSet 详解
private static final Object PRESENT = new Object();
和HashSet一模一样的套路,TreeSet是对TreeMap的封装,只是里面的Entry<K,V>中的value全都指向默认的空对象。
TreeSet和HashSet都有去重的效果,谁更胜一筹呢?自行思考两者的利弊。
WeakHashMap 详解
本质上也是HashMap,主要的却别在于容器内部对键的管理,WeakHashMap是弱引用,gc时会被忽略掉,如果没有其他强引用指向该键的话,那么这个键值对就会从WeakHashMap中移除。比较适合做临时缓存的场景。
总结
今天这篇文章基本上讲清楚了 Java 集合框架中的所有常用实现类的底层原理,加油吧,少年。
2025/01/25
writeBy kaiven