初始MySQL
MySQL 的客户端/服务端架构
这个我觉得没有什么好说的,无论是客户端还是服务端,本质上都是跑在机器上的一个软件而已。这是一个通用型的软件架构模式,客户端和服务端只需要遵守约定好的协议,就能够实现通信。客户端和服务端互不关心对方的实现,双方利用网络或其他方式进行通信。
MySQL的安装
windows:https://blog.csdn.net/eternal__day/article/details/143277037
Linux:https://blog.csdn.net/LIU_ZHAO_YANG/article/details/135628320
客户端与服务器连接过程
有三种通信方式:
- 基于TCP/IP(重点)
- 命名管道和共享内存(了解)
- UNIX 域套接字(了解)
1、基于 TCP/IP
不仅是 MySQL,绝大数的客户端/服务端架构的底层通信协议都是TCP/IP。
这里不是“计算机网络”的相关章节,所以并不会多讲。
TCP/IP是现在通用的一种网络体系结构,其中TCP和IP是两个非常重要的通信协议。IP协议用于寻找指定的主机,TCP协议用于建立连接。
MySQL的客户端与服务端的通信,就是在TCP连接已经建立完成的基础上进行的。
2、命名管道和共享内存(了解)
了解一下就行了,命令管道是windows上特有的东西,共享内存就不用多说了嘛。
3、UNIX 域套接字(了解)
使用这个的前提是服务器进程和客户端进程都运行在类Unix的同一台机器上,就可以使用这玩意儿了。
和 2 是差不多的,运行在同一台机器上,玩什么客户端/服务端架构啊?
服务器处理客户端请求
无论是怎么连接的,最后的效果都是:
客户端发送了一段文本(SQL语句),服务端响应了一段文本(结果)。
现在,我们来简单的探究一下,服务端从接受请求一直到响应结果的这段经历。
上图(以查询请求为例):
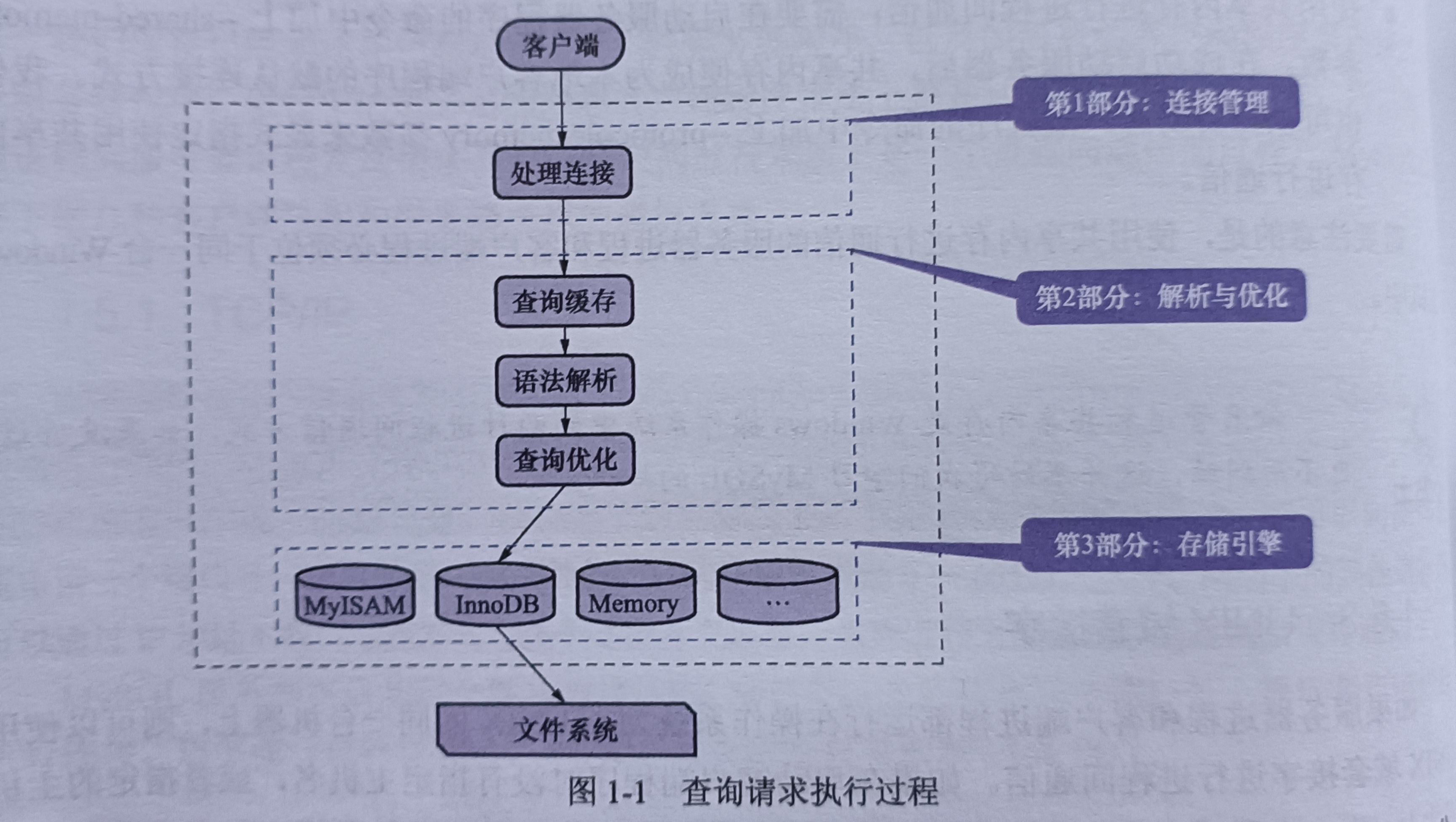
连接管理
当客户端的连接请求到达时,MySQL 都会创建一个线程与该客户端进行交互,与客户端的连接断开时,该线程不会被销毁,而是被缓存起来给下一个客户端使用。
MySQL服务端都有一个最大的客户端连接数配置的,超过最大限制的连接请求将被拒绝。
查询缓存
MySQL服务端会将客户端执行的每一次的查询结果都缓存起来,下一次如果有相同的SQL查询语句时,就可以直接走缓存,加快查询效率。
既然是缓存,那肯定有失效的时候,如果表结构或者数据被修改了的话,表对应的所有查询缓存都会失效,从缓存中移除。
虽然查询缓存可以调高性能,但是维护缓存也会造成一些开销。MySQL 官方不推荐使用查询缓存了,MySQL 8.0版本中直接剔除掉了。(即8.0之前的版本还是存在的,可以手动关闭)
语法解析与查询优化
MySQL会对我们写的SQL语句进行一些解析和优化操作,最终的结果就是生成一个执行计划。通过对执行计划的分析,我们可以知道该SQL语句的执行情况。
存储引擎
负责与硬盘中的数据进行交互,MySQL支持多种存储引擎,默认的存储引擎是 Innodb。
根据这一点,我们可以将MySQL服务端简单的划分为server层和存储引擎层。
server层负责多用存储引擎提供的接口获取数据返回给客户端。不过,这个过程一般是以记录为单位的,举个例子:
一条select * from table where id = 3这条查询语句,server层根据执行计划,先想存储引擎去一条记录,然后判断其id是否等于3,如果符合,那就发送给客户端,不符合就下一条,直到没数据为止。
当然,这样一条又一条的发送显然效率不高,网络I/OC成本太大,都是写入缓存区,缓存区满了之后,再向客户端发送数据。
常用的存储引擎
这里贴一篇文章,先大概了解一下就行了:https://www.cnblogs.com/lgx211/p/18502000
关于存储引擎的一些操作
我给你讲一下有哪些操作,然后自行百度语句:
- 查看当前MySQL服务端支持的所有存储引擎
- 创建表时指定存储引擎
- 修改表的存储引擎
总结
本章内容还是比较简单的,没有什么需要特别加强理解的地方。
2025/01/02
writeBy kaiven