Innodb 数据页结构
数据页的基本结构
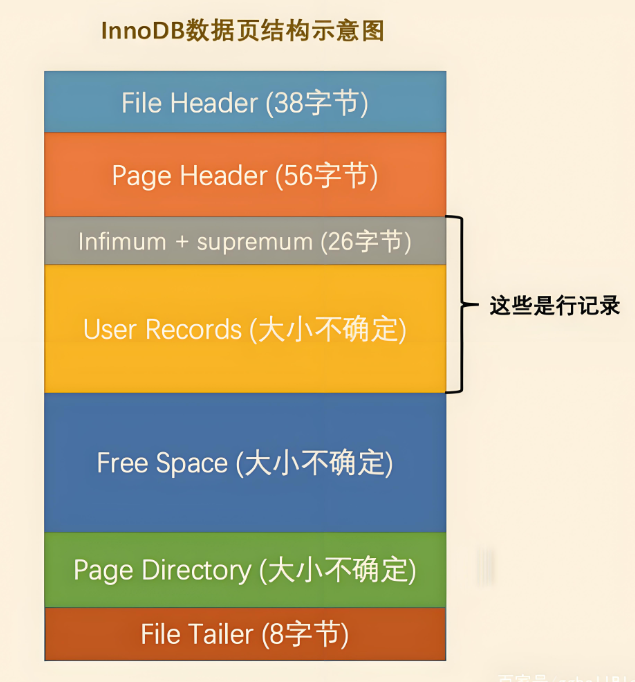
Innodb 中有很多不同类型的页,但是今天只聊与数据存储相关的数据页,当然,官方名称是索引页(鉴于目前这个名称不好理解,暂时叫做数据页吧)
这里解释一下:
File Header
文件头部,存储页面的一些通用信息
Page Header
页面头部,页专有信息
Infimum + supremum
两条固定的虚拟记录,最小记录 + 最大记录
User Records
真实数据存储区域
Free Space
空闲空间,该页中未被使用的空间
Page Directory
页目录,页中某些记录的相对位置
File Trailer
文件尾部,校验页是否完整
(以上内容,有个印象即可)
记录在页中的存储
一个简单的过程开启:
刚开始,并没有User Records这么一说,都是Free Space,当用户插入数据的时候,就会从Free Space中申请空间,存放数据。当该页Free Space不足时,则会申请新的页面继续存储。
我们来探讨一下细节:
1、揭开行格式部分属性的神秘面纱

还是这幅图,代表记录头信息,数据页中的每一行记录都会拥有。
(下面的描述可能和图中不太一样,但是表达的意思是相同的)
delete_flag删除标志位,占用一个比特位,值为
0表示未删除,值为1表示已删除。是的,MySQL 并不会真正的将数据从磁盘上移除,而是打上一个
删除标记,被删除的记录会组成一个垃圾链表,方便空间的重复利用。想象一下,如果真的将一条记录删除了,后续的记录是不是要移位补齐,性能消耗比较大。
heap_noMySQL 将
User Records部分称作堆,heap_no代表记录在堆中的相对位置,新插入的记录总是比前一条记录的heap_no值大1。即,heap_no的值越小,在页面中越靠前。值得注意的时,MySQL 在
User Records中会默认的插入两条虚拟数据,就是上文提到过的Infimum + supremum,分别代表最小记录和最大记录,它们的heap_no值分别是0和1。也就是说,这两条虚拟记录在页中的位置最靠前。heap_no值在确定之后,就不会发生改变了。record_type表示
记录的类型,- 值为
0表示普通记录 - 值为
1表示B+树非叶子节点的目录项记录(稍安勿躁,后续会详细讲解) - 值为
2表示Infimum 记录 - 值为
3表示supremum 记录
- 值为
next_record非常重要的一个属性,表示下一条记录与当前记录的偏移量,值为正数,表示下一条记录在当前记录的后面,值为负数,表示下一条记录在当前记录的前面。
本质上是维护了一个链表结构,链表的头节点就是
Infimum,链表的尾节点就是supremum。头节点的下一个节点就是该页中主键值最小的记录,尾节点的上一个节点是该页中主键值最大的记录。(这里需要注意的是,与插入顺序是无关的)
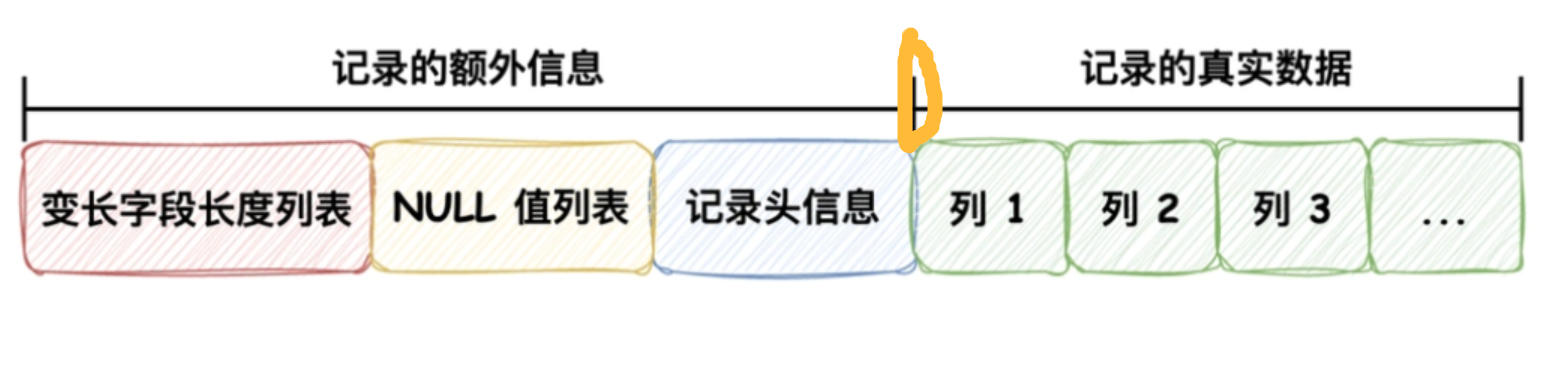
实际上,
next_record指向的是下一条记录的额外信息和真实数据的中间。为什么这么设计呢?
本质上是利用
局部性原理,靠前的字段可以更快速的获取自己的描述信息,提高高速缓存的命中率,这也就是为什么要逆序存放的原因。
Page Director(页目录)
一个数据页中可能有很多条记录,上文也提到过,这些记录以链表的形式,按照主键顺序排列。
查找属于的时候,如果遍历页中的所有记录,那么效率简直不要太低,我们没有利用到条件有序这个特点(目前来说,是按照主键进行的顺序排列)。
有序的列表中查找,最快的算法肯定是二分查找,该算法体现的是一种分而治之的思想。
MySQL 将页中的记录进行分组,每一组有一个“组长”,这个“组长”就是主键值最大的那条记录,“组长”的记录头信息的n_owned属性值代表组内有多少个成员,即多少条记录。取每个“组长”相对于所在页的地址量,放入页目录当中,占用一个Slot,也就是槽位,每个Slot的大小是2字节。
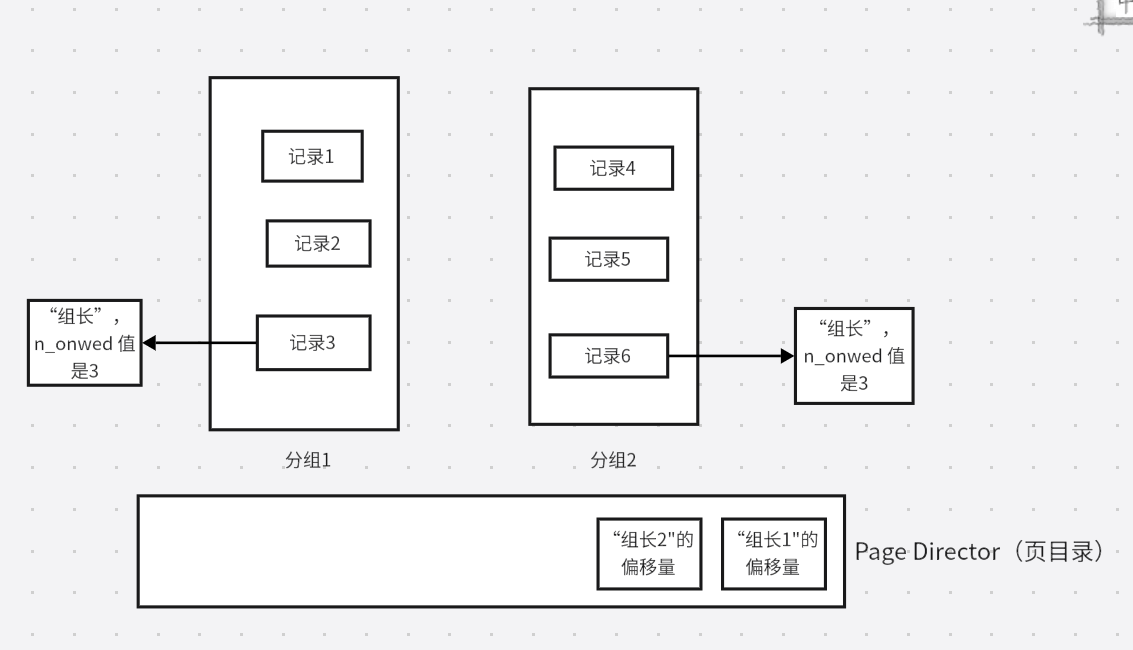
(画得有点抽象,将就看)
这里需要注意一点,User Records中的最大记录和最小记录也会参与分组。
当然,分组也不是随便分的,这里有规则:
Infimum记录单独为一组,即该组只有一条记录supremum记录所在组的成员数量在1~8条,“组长”肯定是supremum- 剩余的记录按照每组
4~8条来进行组队,“组长”是主键值最大的记录
Page Header(页面头部)
可以理解为记录了页面的一些元信息(描述信息):

不要惊慌,饭要一口一口的吃,东西要一点一点的学(一定要沉住气,不要被这些名词吓到)。
这里先"唠叨"PAGE_DIRECTION和PAGE_N_DIRECTION:
PAGE_DIRECTION
表示最后一条记录的插入方向,我们规定,插入记录的主键值比上一条记录的主键值大,是向右插入,否则就是向左插入。
PAGE_N_DIRECTION
如果连续好几条数据都是同一个方向的插入,会更改这个计数器,否则计数器清零,重新计数
剩余的那些属性,后面会慢慢解开其神秘的面纱。
File Header(文件头部)
和Page Header类似,不过它描述的是一种通用页信息:
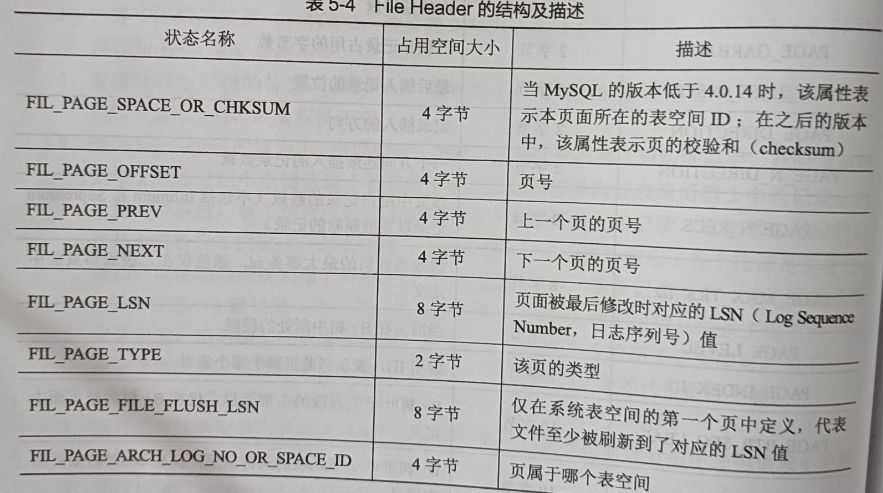
同样的,这里只会“唠叨”一些目前知识铺垫,能够理解的:
FIl_PAGE_SAPCE_OR_CHKSUM
图片上的描述信息已经很清楚了,这里解释一下校验和。就是通过某种算法,对文件内容进行“压缩”,比较的时候先比较
校验和,如果校验和都不相等的话,那么就没比较仔细的比对文件内容了。(比如说 MD5 算法)FIL_PAGE_OFFSET
页偏移量,相对于表空间而言的(有这个印象就行了),也可以叫做页号,通过它可以定位到某个页的具体位置。FIL_PAGE_TYPE
页类型,Innodb 中有很多种不同类型的页: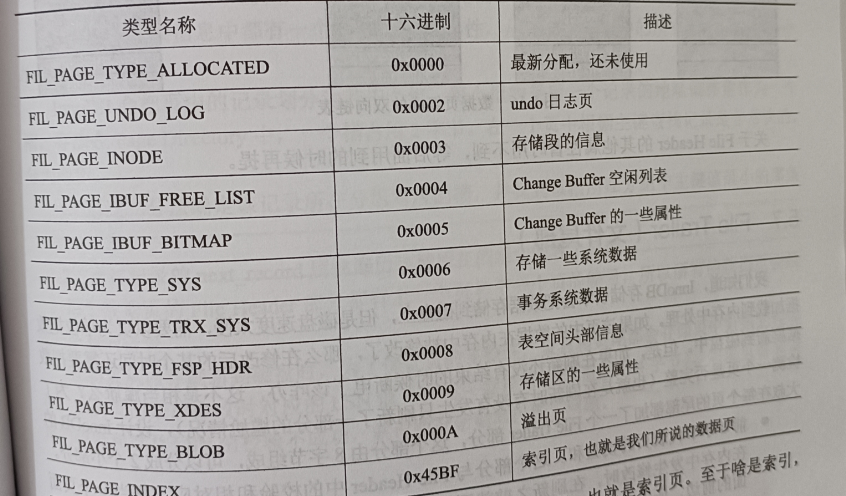
我们描述的数据页,它的FIL_PAGE_TYPE就是FIL_PAGE_INDEX。(其他类型的页遇到了在详细说)
FIL_PAGE_PREV 和 FIL_PAGE_NEXT
你也猜到了,
表空间中的页可以是不连续的,通过前后的指针(偏移量)构成了一个双端链表结构。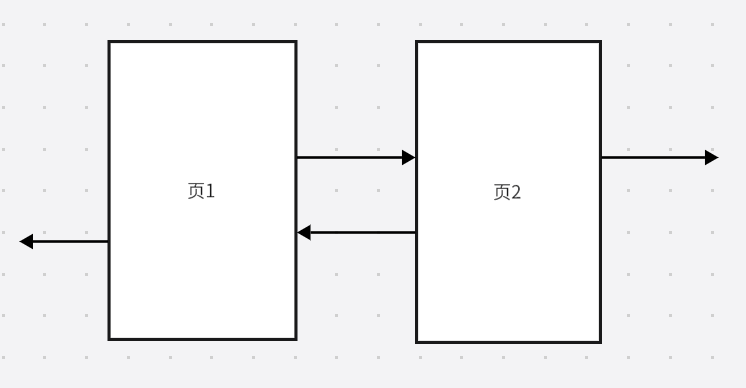
虽然有点丑陋,但是你应该能够理解
File Trailer(文件尾部)
最开始提到过,可以用于校验文件的一致性和完整性。如果你仔细越多了File Header部分,你也会发现,为什么File Header中已经有了校验和以及其他一些修改记录参数,File Trailer中还要去冗余呢?
这是为了防止页面从内存刷新到磁盘的过程中,突然断电,只刷新了一部分而产生的数据不一致的情况。文件的头部先刷入到磁盘中,如果断电重启了,那么页面的File Header和File Trailer中的参数就会不一致,能够检测到数据的刷盘出现了问题。
总结
今日份内容,相对较多,需要不断的反复加深记忆。
2025/01/28
writeBy kaiven