概念
在之前的章节中,我们已经知道了,innodb中的数据是以页为单位存储在磁盘上的。磁盘的读写效率肯定是不能和内存的读写效率相比较的。
我们来看这条sql语句:
select * from tb_user where id between 20 and 1000;
- 取id为1的数据时,一次I/O
- 取id为2的数据时,一次I/O
- 取id为3的数据时,一次I/O
- ......
根据上文我们学过的innodb数据存储的知识,会发现id为【1,2,3】的数据其实都在一页中,直接读取一页或多页的数据放入内存中,不就可以减少I/O消耗了嘛,于是设计出了buffer_pool缓冲池:
- 取id为1的数据时,一次I/O
- 取id为2的数据时,查询缓存,无I/O
- 取id为3的数据是,查询缓存,无I/O
- ......
innodb存储引擎在MySQL服务启动的时候,会向操作系统申请一块连续的内存空间当做buffer_pool,空间的大小有变量buffer_pool_size决定:
show variables like 'innodb_buffer_pool_size';
这个缓冲区的大小可以结合实际的软硬件场景而定,不过我们的MySQL都是单独部署的,所以一本为系统内存的60% ~ 70% 即可。
内部结构
整个buffer_pool是由缓冲页和控制块组成的:
**缓冲页:**buffer pool中存放的【数据页】我们称之为【缓冲页】,和磁盘上的数据页是一一对应的,都是
16KB,缓冲页的数据,是从磁盘上加载到buffer pool当中的一个完整页。
**控制块:**他是缓冲页【描述信息】,这一块区域保存的是数据页所属的表空间号,数据页编号,数据页地
址,以及一些链表相关的节点信息等,每个控制块大小是缓存页的5%左右,大约是800个字节。
其内部结构如下,buffer pool的前一部分存储【控制块】,后一部分存储【缓冲页】,如果中间有未被利用的空
间,就叫它【内存碎片】吧:
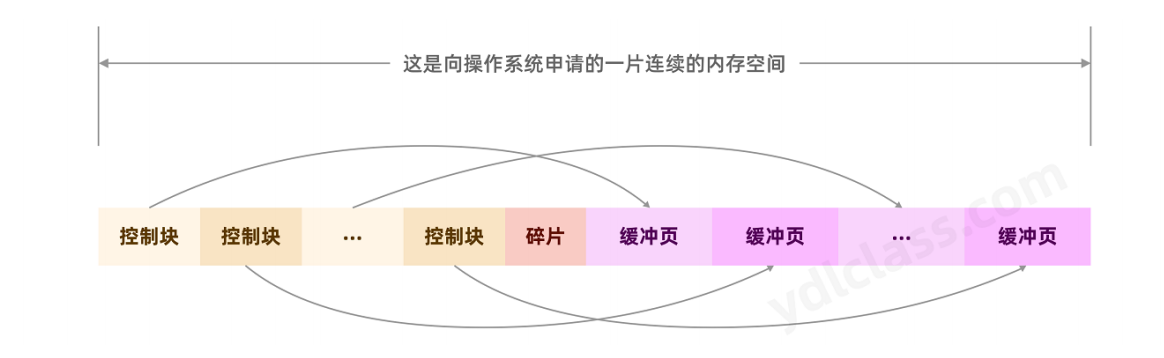
(当然,你也可以做到没有碎片化的,这个看你怎么设置buffer_pool_size了)
free 空闲链表
刚初始化的buffer pool,内存中都是【空白的缓冲页】,但是随着时间的推移,程序在执行过程中会不断的有新的页被缓存起来,那怎么来判断哪些缓冲页是【闲置状态】,可以被使用呢,此时就需要【控制块来进行标记和管理】了。innodb在设计之初,会将所有【空闲的缓冲页】所对应的【控制块】作为一个个的节点,形成一个链表,这个链表就是free链,翻译过来就是空闲链表,如下图:
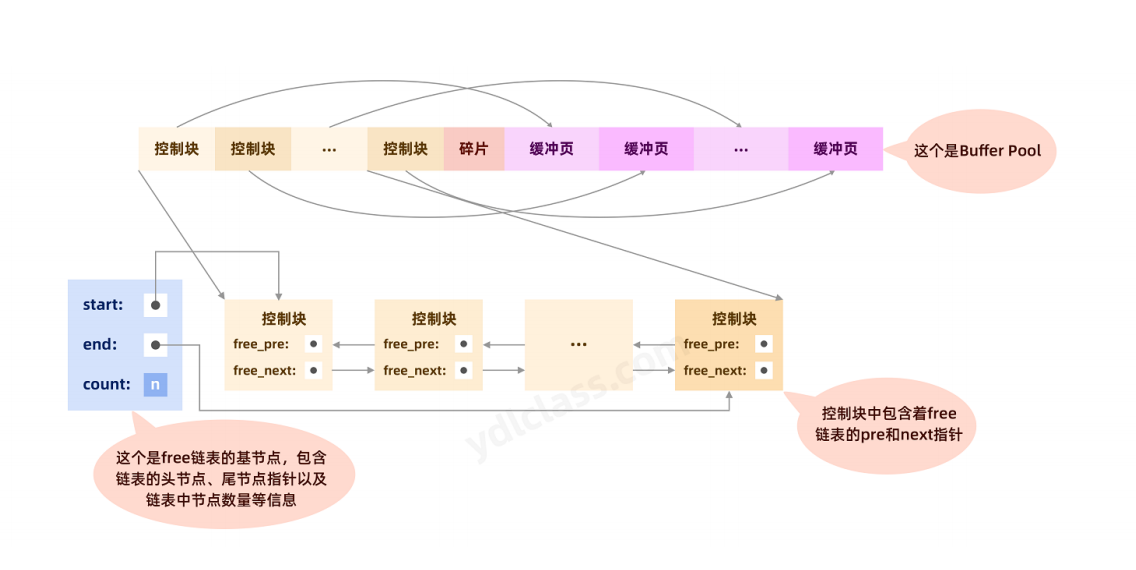
由上图可知,free链表是一个双向链表,链表上除了控制块以外,还有一个基础节点,存储了free链有多少个描述信息块,也就是有多少个空闲的缓存页,以及指向链表头尾的指针。
当我们加载数据的时候,会从free链中找到空闲的缓存页,把数据页的【表空间号和数据页】号写入【控制块】。加载数据到缓存页后,会把缓存页对应的控制块从free链表中移除。
怎么知道数据是否被缓存?
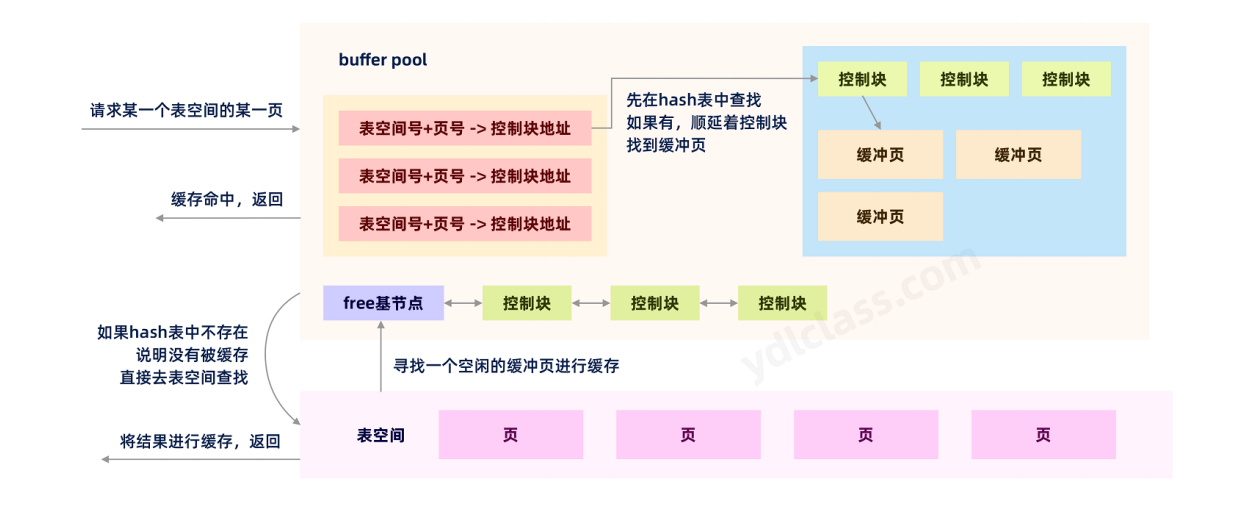
我们已经有了free链表用来【保存空闲的页】,但是,当下一次访问时,要如何知道当前要访问的页是不是已经被缓存了,最直观的思路就是将buffer poll里的缓存数据【全部遍历一遍】。显然,这要做并不合理,本来设计buffer pool是为了提升效率,如果有人将buffer pool配置的很大,比如32个G,那扫描这一片区域的功夫都可以喝一杯茶了,反而成了累赘。
事实上,使用【表空间号+页号】就可以确定一个唯一的页,那么我们能不能设计一个hash表,使用【表空间号+页】号当做key,使用【控制块地址】做value,每次查询的时候只需要通过key进行查找即可,大家都知道hash的时间复杂度是O(1),这样就能迅速定位缓存的页。(和hashmap很像)
结合我们的free链表,查询/缓存一个页的流程大致如下:
flush链表
脏页
在sql的执行过程中,无论是增删改查,都是优先在buffer pool中进行的,这样可以极大的保证执行效率。但是同样会有一个问题,假如我们对缓存页的某些数据进行了修改(执行了一条update语句),就会导致buffer pool中的缓冲页和磁盘的数据页【数据不一致】,那么此时的缓冲页就称之为【脏页】。当然,这也就说明了,脏页的数据是要刷到磁盘上的。
链表结构
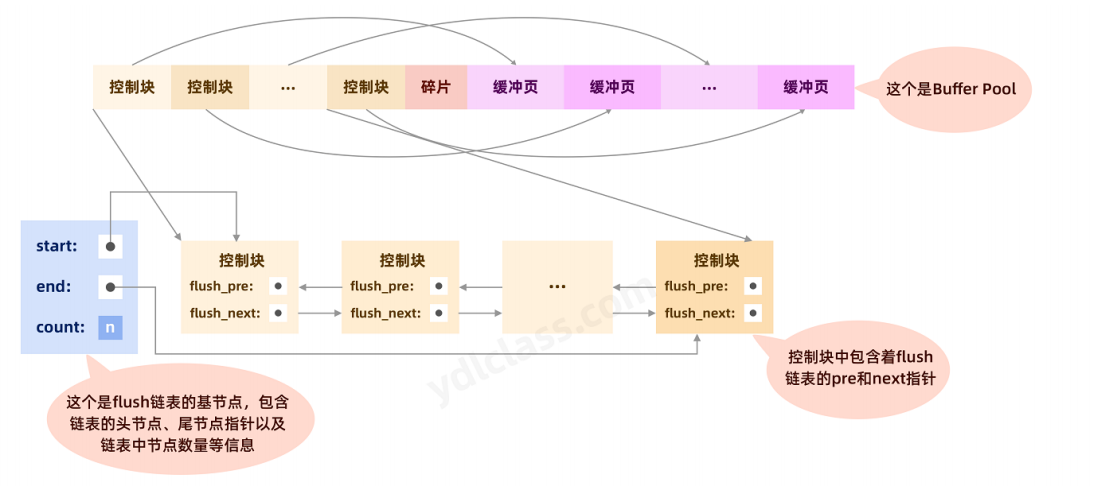
- flush链表同样是一个双向链表,链表结点是被【修改过的缓存页】的控制块。
- 和free链表一样,flush链表也有一个基础结点,链接首尾结点,并存储了有多少个控制块。
刷盘时机
后台会有专门的线程每隔一段时间就把flush链表中的脏页刷入磁盘中,刷新的速率取决与当前系统是否繁忙。在这样的机制下,万一系统奔溃,是会产生数据不一致的问题的,没有刷入磁盘的数据就会丢失,而mysql通过日志系统解决了这个问题,以后的章节会详细讲解。
LRU 链表
概述
内存是有限的,buffer pool更是有限的,缓存只是数据的中转站,当我们的数据量很大以后,buffer pool其实是仅仅能容纳很少一部分数据,所以buffer pool的容量很有可能被使用殆尽,如果此时我们还想继续缓存数据页那该怎么办?
合理的做法就是,当需要更多的空间缓存【新的数据页】的时候,我们将最近使用最少的【缓冲页淘汰掉】就可以了,这就是典型的LRU(Least Recently Used)算法。对于innodb而言,则是通过【LRU链表】来完成此功的,它的结构和上边讲的free链表、flush链表基本相同,只是负责的功能不同而已。
于是,一个简单的思路诞生了,当客户端访问一条数据时,会加载对应的数据页到buffer pool,并会将缓冲页对应的控制块放置到【LRU链表的首位】。一旦buffer pool被占满,则从链表的末端开始淘汰数据,这是最简单的实现。
优化
但是,实际的在使用场景中,我们需要对原有的LRU链表进行优化,因为他在以下场景可能会出现一些问题:
innodb从磁盘读取数据,也不一定是一页页读取,当mysql读取当前需要的页时,如果觉得后续操作会使用【附近的页】,就会将他们一起缓存到buffer pool,这样的作用是为了提升效率。但是,这也会导致大量的使用频率并不高的数据放置在LRU链表头部,反而将一些真正的【热点数据】淘汰。
全表扫描:一条【select * from user】 语句,会直接将一张表的全表数据缓存,并全部放在LRU链表头部,
一样会淘汰很多热点数据。
所以,innodb对该链表进行了优化,将【LRU链表】分成了两个区域,分为【热数据区】和【冷数据区】,默认情况下冷数据区占了总链表的37%:
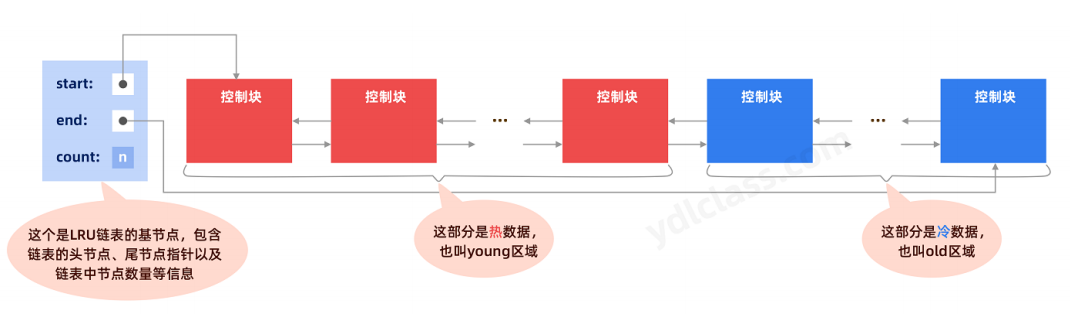
一个select语句可能会多次访问一个页,因为你有【很多数据是保存在同一个页内】的。对于一个全表扫描的语句,每访问一条数据,就会访问一次相关的页,所以缓存确实能极大的提升效率:
对于预读的数据页,会在第一次访问时放入old区域,如果在sql执行的过程中访问相邻数据时,再次访问访问
到该数据页,则把他加入如热数据区。
【大表的全表扫描】是个使用频率很低的操作(小表怎么操作都无所谓),但是如果按照上边的操作,首先
全表数据会被放在【old区】,全表扫描必然会因为访问相邻数据而产生第二次、第三次、甚至数百次的访
问,也就以为着这些页面会被全部放在young区。为了解决这个问题,INnodb提供了这样一个参数
【innodb_old_blocks_time】,默认是1s,他的执行流程大致如下:
页被首次访问时会记录访问的时间戳。
以后访问都和首次访问的时间进行对比,如果时间大于1s,就讲当前页放入yong区。
一个sql的扫描一个页的时间,哪怕在慢也不会低于1s,这样就解决了一个全表扫秒而导致全表成为热点
数据的问题。
(这也就意味着,热点数据要求首次访问时间和最后一次访问时间的时间差不能低于1s)
show variables like '%innodb_old_blocks_time%'
show engine innodb status # 查看当前innodb的状态
2024.11.07
writeBy kaiven